


« 2021年11月 | 2021年12月のアーカイブ | 2022年01月 »
2021/12/16
オーディオマニア向けイーサネットスイッチ
https://gigazine.net/news/20211215-ethernet-switch-for-audiophiles/
約26万円の「オーディオマニア向けイーサネットスイッチ」の話題。

オカルトだなんだと言われるこの手の話は昔からあるけど、自分的解釈としては聴いている人にとっては確かに良い音に聴こえるのだと思う。ただしその人にとってはという話。
プラセボと呼ばれては身も蓋もないが、音の良し悪しというのは聴覚刺激を脳がどう判断するかである以上、聴く時の精神状態に依存して感じる音が変化するのは当然だと思うし、良い音を感じやすいように精神状態を整えるのは意味があると思う。
同じ曲を長時間ミックスしていると同じ設定にしても場合によって全然違って聴こえるなんてのは普通の事。
同じ音源を聴いてもゴミ屋敷みたいな部屋で聴くのと良い音がでそうな部屋で聴くのとで同じ評価が下せるとは思えないし、自分の信じる一番良い音が出る機器を使うというのはある意味重要。人によっては一番良い音と感じやすくなる香りとか、料理とかもあるんだろうな。
脳が聴覚から受ける刺激の質を問うのであれば、そんな事よりもこの10年で加齢により可聴周波数の上限が数kHzは下がっている事の方がはるかに深刻ではある。人間の耳の特性は刻々と変化している。が、音の良し悪しは刺激を受け取った後の脳がどう判断するかという話なので、良い音を感じやすい環境は重要だとは思う。
そこにおかしな理論で無理に技術的裏付けを付加しようとして批判を受けるというのもありがちだけど。
まあ私は別にオーディオマニアではないので、基本的には気にしない。
posted by g200kg : 8:21 PM : PermaLink
2021/12/07
耳の話の続き
先日、「耳の話」なんかを書いたのでその辺りの話をもう少し書いてみます。
耳の奥、蝸牛は AGC (Auto Gain Control) 機能付きの高性能アクティブセンサーである、みたいな話だったのだけど、その有毛細胞によるフィルタバンクで周波数分析された音声信号はそのままパラレルに脳のニューラルネットに入力されるわけですが、これってそのまま「スペクトログラム」なんですよね。横軸が時間、縦軸は周波数でどの部分にエネルギーが存在しているかを表すグラフです。あの声紋分析なんかで使われる奴です。
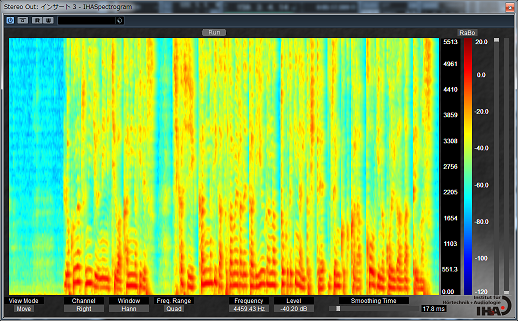
コンピュータによる音声認識でも同じように入力された音声はまず FFT とかで周波数分析しますが、問題はこのあとどう処理するかです。母音の判定をするためにフォルマントを抽出してみたりフォルマントの時間的な動きを抽出してみたり、音素を判定してみたり、HMM で辞書と比較してみたり、とこれまでに様々な職人芸的音声処理が試行錯誤されてきたのですが、徐々に改善はされるものの中々精度が良くならない、という時代がコンピュータの黎明期からずっと、50年近く続いていたわけです。この時代は多分認識の精度としては精々70%~80%くらいだったかと思います。フォルマントの動きを特徴量として抽出して隠れマルコフモデル(HMM)で判定するというのがこの時代の代表的なやり方でした。
そして音声認識というとあまり実用的じゃないなというのが実際の所の評価。アプリケーションを限定すれば使えるケースもあるかも知れない、という程度。認識を2択、3択等に限定すればそれなりに動くけど間違っても許してね、という感じ。
それが2000年代頃に登場したディープラーニングの応用でいきなり様相が変わります。DeepMind社のWaveNetとかですね。割とすぐにGoogleに買収されましたけど。今までより明らかに優れた認識精度! これは職人芸的な様々な判定手法じゃなく、とにかく抽出したフォルマントとかの特徴量をまとめてニューラルネットに放り込んで大量の学習データでぶん回せばなんとかなるんじゃないかという丸投げ方式ですが、これが今までの緻密にチューニングを繰り返してきたやり方をあっさりと上回る品質が出てしまったわけです。
そして更に10年ほど経った2010年代、再びショッキングな事実が明らかになります。
最終的な判定にニューラルネットを使うとしても、入力する前段階の処理としてこれまではフォルマントの動きやらを職人芸的手法で抽出していたのですが、もしかしてこれ、要らないんじゃね? と。そして周波数分析をした後のスペクトログラムをそのまんまニューラルネットにぶち込んでも学習さえちゃんとやれば動作するんじゃね? と。
そして案の定職人芸の敗北。周波数分析とニューラルネットだけを使って大量の学習データをぶん回す事で、より良い結果が出てしまいました。この構造は図らずも人間の耳から脳に周波数分析データをパラレルにぶっこんでる構造と同じ、職人芸的ロジックとかはどこにも入っていません。ある意味ずいぶんシンプルになってしまいました。ニューラルネットの中身というのは割とブラックボックスなのでミクロな視点で何がどうなってこういう結果が出るのかと言われると説明は難しい事になってしまいましたが、言葉を知らない赤ん坊が大量の言葉を聴いて覚えていくように人間がロジックをこねくり回すよりも自然現象として言葉をおぼえてしまう、みたいな事になっています。
シンギュラリティポイントの始まりみたいなものを感じますね。今後どうなるんでしょうね。
posted by g200kg : 6:21 PM : PermaLink
2021/12/05
耳の話
聴力テストを作ったりしたので、ちょっと耳系の話も書いてみます。
人間が音を感じるセンサーになる部分は耳の奥、内耳にある蝸牛と呼ばれる器官です。なんとなくイラストを見たりした事があるかも知れませんがあのカタツムリみたいな奴、乗り物酔いの原因にもなる有名な三半規管とくっついている奴ですね。

鼓膜からの振動はこの蝸牛に伝えられるわけですがそこには数万個の有毛細胞があり、その内の3500個程度が内有毛細胞というもので機械的な振動に反応するようになっています。そしてそれぞれの内有毛細胞は特定の周波数と共振してここで周波数分析が行われます。これは言わば物理的なフィルタバンク、凄いですね。そして内有毛細胞からの信号はそのまま全部パラレル(!)に脳のニューラルネットに送り込まれるわけです。人間は音程には敏感だけど位相は殆ど認識できないというのはこういう構造で脳への入力信号がそもそも周波数毎のマグニチュードしかなくて位相情報が取れていないからなんでしょうね。
数万個の有毛細胞の内、振動に反応する内有毛細胞が3500個程度、すると残りの外有毛細胞と言われる部分は何なのかというと、この辺はまだ完全に動作が解明されていないらしいのだけど、どうやらセンサーではなくモーターらしいという興味深い事がわかっているようです。つまり刺激を受けて脳に信号を送るのではなく、信号を受けて能動的に動く。しかも音声信号レベルで高速に動いて自ら音を発している!! なんと!!
つまり耳が音を聴いていると思ったら耳から音が出ている!
このセンサーとモーターが組み合わさってどうやら信号の非線形な増幅装置が構成されているというのが定説となっています。このため、単体で摘出された蝸牛で何が起こっているのか確認しようと実験してもどう考えてもマイクとしての感度が低すぎる。生体の中でのみ稼働するアクティブセンサーらしいのです。
この耳から出てくる音は耳音響放射と言い、実際に耳に音を入力した時に耳から出てくる音を測定して内耳の機能検査などで使用されています。
人間の耳が音の大きさに対して対数的に反応し、ぎりぎり聴こえるかすかな音からジェット機の爆音まで120dBの幅の大きさの音に対応できるのはこのアクティブ機構があるからのようです。
凄すぎるだろ、耳。
posted by g200kg : 5:51 PM : PermaLink
2021/12/04
聴力テストを作ったのだが...【悲報】12kHzが聴こえなくなりました
モスキート音、どこまで聴こえてますか?
という事で聴力テストを行うページを作りました。
GitHub に置いてあります。
実行ページ : https://g200kg.github.io/auditory-test/
リポジトリ : https://github.com/g200kg/auditory-test
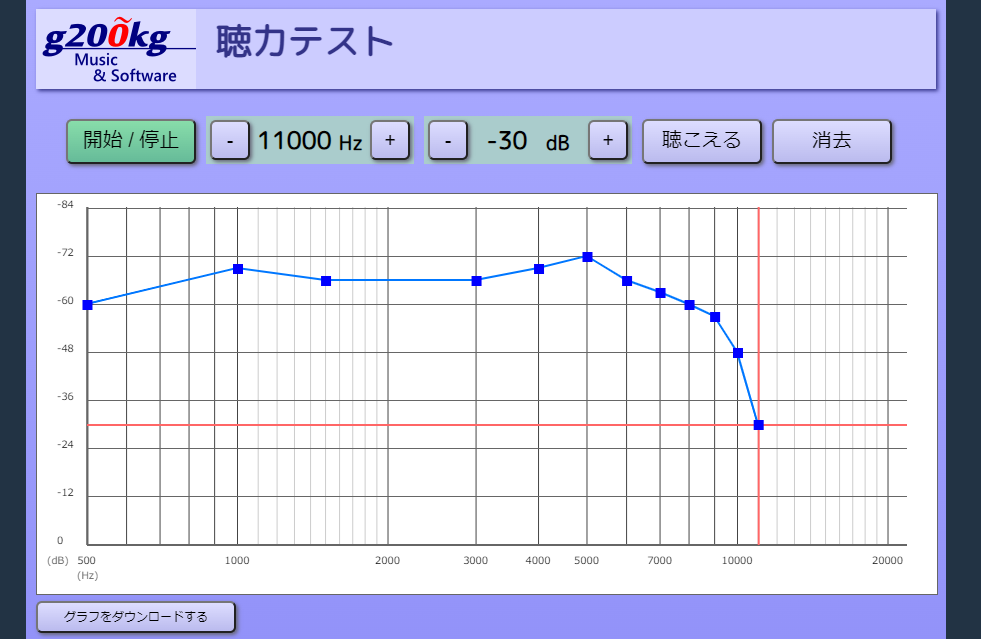
再生環境にもよりますので正確とは言えませんが、目安にはなると思います。どうやらもう12kHzあたりが限界ぽいです。
加齢と共に高い周波数の感度が下がるのは今更どうこう言ってもしょうがない事なのだけど10年前くらいなら聴こえていたはずの音が聴こえないのは残念な話です。まあ所詮人間の耳なんてそもそも犬とかに比べると全然聴こえていないんですけどね。
耳の特性が変わっていくのだから同じ音源を聴いても脳が10年前と同じ刺激を受け取る事は出来ない、という事実についてオーディオマニアな人達はどう折り合いを付けているのだろうかとか思ったりはする。
ヘッドホンでガンガン音量を上げるのが好きな人とかは後で後悔するから程度を考えた方が良いです。
posted by g200kg : 11:28 AM : PermaLink
« 2021年11月 | 2021年12月のアーカイブ | 2022年01月 »
-->
g200kg